Shift Tables with flextable
# remotes::install_github("davidgohel/flextable")
library(flextable)
library(tidyverse)
library(safetyData)
use_df_printer()
set_flextable_defaults(
theme_fun = theme_booktabs,
big.mark = " ",
font.color = "#666666",
border.color = "#666666",
padding = 3,
)Introduction
Shift tables are tables used in clinical trial analysis.
They show the progression of change from the baseline, with the progression often being along time; the number of subjects is displayed in different range (e.g. low, normal, or high) at baseline and at selected time points or intervals.
The two steps for the creation of these tables are the following:
- Do the calculations, for this we will use function
flextable::shift_table(). It calculates the counts and aggregates these counts according to different dimensions in order to display subtotals. - Create a flextable with function
as_flextable().
We used the article by (Luo 2017) to help us understand shift tables.
Sample data
We will illustrate with a dataset named sdtm_lb containing Laboratory Tests Results and available in
the “safetyData” package. From the manual of sdtm_lb, it contains:
One record per analyte per planned time point number per time point reference per visit per subject
adlb <- safetyData::sdtm_lb %>% as_tibble() %>%
filter(LBTEST %in% c("Albumin", "Alkaline Phosphatase"),
grepl("(WEEK|SCREENING)", VISIT))
adlbSTUDYID | DOMAIN | USUBJID | LBSEQ | LBTESTCD | LBTEST | LBCAT | LBORRES | LBORRESU | LBORNRLO | LBORNRHI | LBSTRESC | LBSTRESN | LBSTRESU | LBSTNRLO | LBSTNRHI | LBNRIND | LBBLFL | VISITNUM | VISIT | VISITDY | LBDTC | LBDY |
character | character | character | integer | character | character | character | character | character | numeric | numeric | character | numeric | character | numeric | numeric | character | character | numeric | character | integer | character | integer |
CDISCPILOT01 | LB | 01-701-1015 | 1 | ALB | Albumin | CHEMISTRY | 3.8 | g/dL | 3.3 | 4.9 | 38 | 38 | g/L | 33 | 49 | NORMAL | Y | 1 | SCREENING 1 | -7 | 2013-12-26T14:45 | -7 |
CDISCPILOT01 | LB | 01-701-1015 | 39 | ALB | Albumin | CHEMISTRY | 3.9 | g/dL | 3.3 | 4.9 | 39 | 39 | g/L | 33 | 49 | NORMAL | 4 | WEEK 2 | 14 | 2014-01-16T13:17 | 15 | |
CDISCPILOT01 | LB | 01-701-1015 | 74 | ALB | Albumin | CHEMISTRY | 3.8 | g/dL | 3.3 | 4.9 | 38 | 38 | g/L | 33 | 49 | NORMAL | 5 | WEEK 4 | 28 | 2014-01-30T08:50 | 29 | |
CDISCPILOT01 | LB | 01-701-1015 | 104 | ALB | Albumin | CHEMISTRY | 3.7 | g/dL | 3.3 | 4.9 | 37 | 37 | g/L | 33 | 49 | NORMAL | 7 | WEEK 6 | 42 | 2014-02-12T12:56 | 42 | |
CDISCPILOT01 | LB | 01-701-1015 | 134 | ALB | Albumin | CHEMISTRY | 3.8 | g/dL | 3.3 | 4.9 | 38 | 38 | g/L | 33 | 49 | NORMAL | 8 | WEEK 8 | 56 | 2014-03-05T12:25 | 63 | |
CDISCPILOT01 | LB | 01-701-1015 | 164 | ALB | Albumin | CHEMISTRY | 3.8 | g/dL | 3.3 | 4.9 | 38 | 38 | g/L | 33 | 49 | NORMAL | 9 | WEEK 12 | 84 | 2014-03-26T15:15 | 84 | |
CDISCPILOT01 | LB | 01-701-1015 | 199 | ALB | Albumin | CHEMISTRY | 3.7 | g/dL | 3.3 | 4.9 | 37 | 37 | g/L | 33 | 49 | NORMAL | 10 | WEEK 16 | 112 | 2014-05-07T11:21 | 126 | |
CDISCPILOT01 | LB | 01-701-1015 | 229 | ALB | Albumin | CHEMISTRY | 3.7 | g/dL | 3.3 | 4.9 | 37 | 37 | g/L | 33 | 49 | NORMAL | 11 | WEEK 20 | 140 | 2014-05-21T10:58 | 140 | |
CDISCPILOT01 | LB | 01-701-1015 | 259 | ALB | Albumin | CHEMISTRY | 3.8 | g/dL | 3.3 | 4.9 | 38 | 38 | g/L | 33 | 49 | NORMAL | 12 | WEEK 24 | 168 | 2014-06-18T13:00 | 168 | |
CDISCPILOT01 | LB | 01-701-1015 | 294 | ALB | Albumin | CHEMISTRY | 3.8 | g/dL | 3.3 | 4.9 | 38 | 38 | g/L | 33 | 49 | NORMAL | 13 | WEEK 26 | 182 | 2014-07-02T11:45 | 182 | |
n: 3546 | ||||||||||||||||||||||
Calculation of the shift table
The calculation of the shift table is a single call to shift_table():
SHIFT_TABLE <- shift_table(
x = adlb, cn_visit = "VISIT",
cn_grade = "LBNRIND",
cn_usubjid = "USUBJID",
cn_lab_cat = "LBTEST",
cn_is_baseline = "LBBLFL",
baseline_identifier = "Y",
grade_levels = c("LOW", "NORMAL", "HIGH"))
SHIFT_TABLELBTEST | VISIT | BASELINE | LBNRIND | N | PCT |
character | character | character | character | integer | numeric |
Albumin | WEEK 12 | HIGH | HIGH | 0 | 0.0 |
Albumin | WEEK 12 | HIGH | LOW | 0 | 0.0 |
Albumin | WEEK 12 | HIGH | MISSING | 0 | 0.0 |
Albumin | WEEK 12 | HIGH | NORMAL | 1 | 0.0 |
Albumin | WEEK 12 | LOW | HIGH | 0 | 0.0 |
Albumin | WEEK 12 | LOW | LOW | 2 | 0.0 |
Albumin | WEEK 12 | LOW | MISSING | 0 | 0.0 |
Albumin | WEEK 12 | LOW | NORMAL | 0 | 0.0 |
Albumin | WEEK 12 | MISSING | HIGH | 0 | 0.0 |
Albumin | WEEK 12 | MISSING | LOW | 0 | 0.0 |
n: 360 | |||||
The data.frame produced is containing attributes that you can use for post-treatments, i.e. transform grades and visits as factor columns.
SHIFT_TABLE_VISIT <- attr(SHIFT_TABLE, "VISIT_N")
visit_as_factor <- attr(SHIFT_TABLE, "FUN_VISIT")
range_as_factor <- attr(SHIFT_TABLE, "FUN_GRADE")
# post treatments ----
SHIFT_TABLE <- SHIFT_TABLE |> mutate(
VISIT = visit_as_factor(VISIT),
BASELINE = range_as_factor(BASELINE),
LBNRIND = range_as_factor(LBNRIND))
SHIFT_TABLE_VISIT <- SHIFT_TABLE_VISIT |>
mutate(VISIT = visit_as_factor(VISIT))
SHIFT_TABLELBTEST | VISIT | BASELINE | LBNRIND | N | PCT |
character | factor | factor | factor | integer | numeric |
Albumin | WEEK 12 | High | High | 0 | 0.0 |
Albumin | WEEK 12 | High | Low | 0 | 0.0 |
Albumin | WEEK 12 | High | Missing | 0 | 0.0 |
Albumin | WEEK 12 | High | Normal | 1 | 0.0 |
Albumin | WEEK 12 | Low | High | 0 | 0.0 |
Albumin | WEEK 12 | Low | Low | 2 | 0.0 |
Albumin | WEEK 12 | Low | Missing | 0 | 0.0 |
Albumin | WEEK 12 | Low | Normal | 0 | 0.0 |
Albumin | WEEK 12 | Missing | High | 0 | 0.0 |
Albumin | WEEK 12 | Missing | Low | 0 | 0.0 |
n: 360 | |||||
In order to have a short table when illustrating, we are going to filter data with only few visits.
SHIFT_TABLE <- SHIFT_TABLE |>
filter(VISIT %in% c("WEEK 4", "WEEK 12", "WEEK 16", "WEEK 26"))Tabulate with tabulator
Now the datasets are ready, we need to define a tabulator object that
can then be passed to as_flextable().
my_format <- function(z) {
formatC(z * 100, digits = 1, format = "f",
flag = "0", width = 4)
}
tab <- tabulator(
x = SHIFT_TABLE,
hidden_data = SHIFT_TABLE_VISIT,
row_compose = list(
VISIT = as_paragraph(VISIT, "\n(N=", N_VISIT, ")")
),
rows = c("LBTEST", "VISIT", "BASELINE"),
columns = c("LBNRIND"),
`n` = as_paragraph(N),
`%` = as_paragraph(as_chunk(PCT, formatter = my_format))
)Production of the flextable
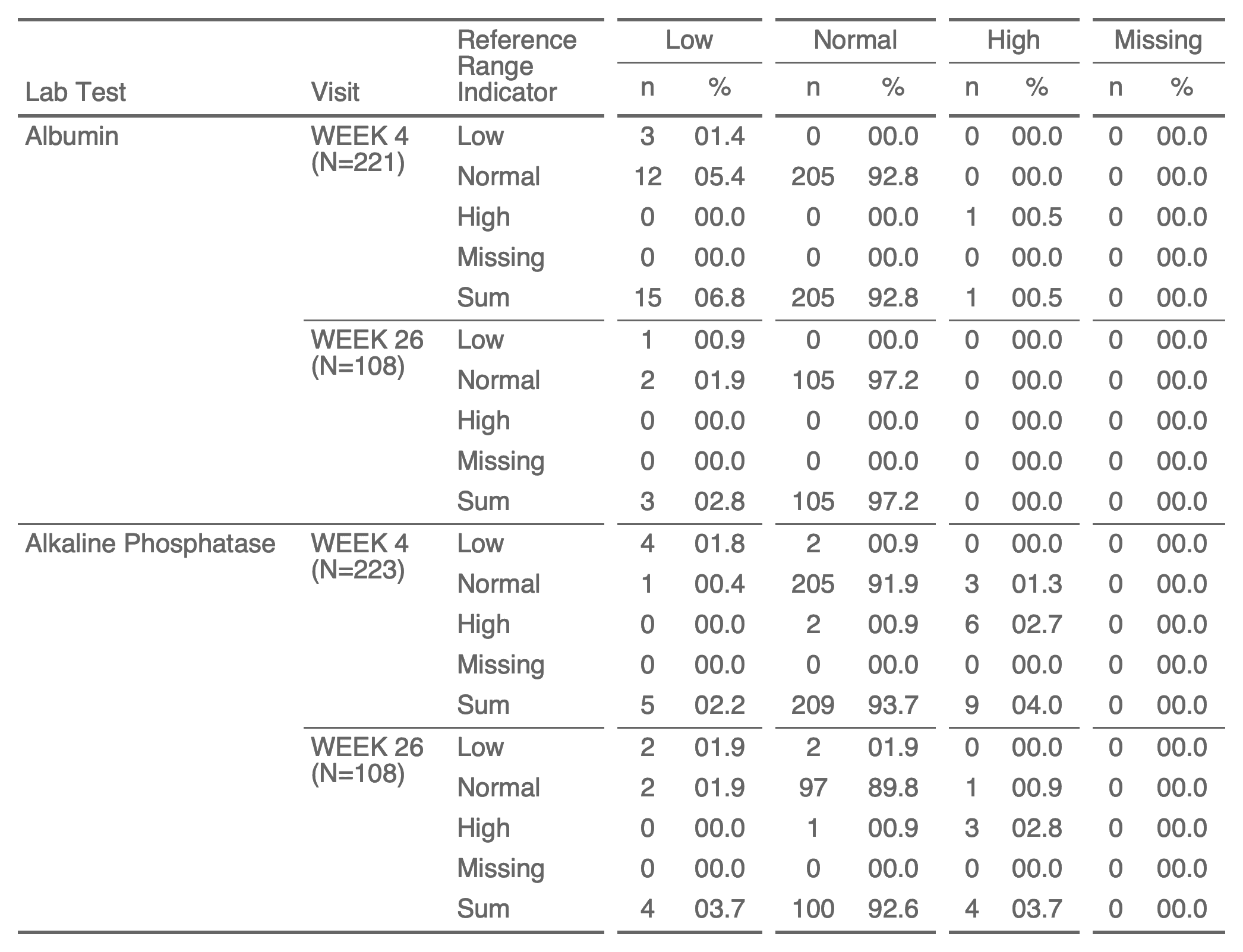
ft <- as_flextable(
x = tab, separate_with = "VISIT",
label_rows = c(LBTEST = "Lab Test", VISIT = "Visit",
BASELINE = "Reference Range Indicator")) |>
width(j = 3, width = 0.9)
ftLab Test | Visit | Reference Range Indicator | Low | Normal | High | Missing | ||||||||
n | % | n | % | n | % | n | % | |||||||
Albumin | WEEK 4 | Low | 3 | 01.4 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||
Normal | 12 | 05.4 | 205 | 92.8 | 0 | 00.0 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 0 | 00.0 | 1 | 00.5 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 15 | 06.8 | 205 | 92.8 | 1 | 00.5 | 0 | 00.0 | ||||||
WEEK 12 | Low | 2 | 01.2 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | |||||
Normal | 4 | 02.4 | 159 | 95.2 | 1 | 00.6 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 1 | 00.6 | 0 | 00.0 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 6 | 03.6 | 160 | 95.8 | 1 | 00.6 | 0 | 00.0 | ||||||
WEEK 16 | Low | 2 | 01.4 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | |||||
Normal | 2 | 01.4 | 139 | 95.9 | 2 | 01.4 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 4 | 02.8 | 139 | 95.9 | 2 | 01.4 | 0 | 00.0 | ||||||
WEEK 26 | Low | 1 | 00.9 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | |||||
Normal | 2 | 01.9 | 105 | 97.2 | 0 | 00.0 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 3 | 02.8 | 105 | 97.2 | 0 | 00.0 | 0 | 00.0 | ||||||
Alkaline Phosphatase | WEEK 4 | Low | 4 | 01.8 | 2 | 00.9 | 0 | 00.0 | 0 | 00.0 | ||||
Normal | 1 | 00.4 | 205 | 91.9 | 3 | 01.3 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 2 | 00.9 | 6 | 02.7 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 5 | 02.2 | 209 | 93.7 | 9 | 04.0 | 0 | 00.0 | ||||||
WEEK 12 | Low | 2 | 01.2 | 2 | 01.2 | 0 | 00.0 | 0 | 00.0 | |||||
Normal | 1 | 00.6 | 154 | 92.2 | 3 | 01.8 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 0 | 00.0 | 5 | 03.0 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 3 | 01.8 | 156 | 93.4 | 8 | 04.8 | 0 | 00.0 | ||||||
WEEK 16 | Low | 2 | 01.4 | 2 | 01.4 | 0 | 00.0 | 0 | 00.0 | |||||
Normal | 1 | 00.7 | 131 | 90.3 | 4 | 02.8 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 1 | 00.7 | 4 | 02.8 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 3 | 02.1 | 134 | 92.4 | 8 | 05.5 | 0 | 00.0 | ||||||
WEEK 26 | Low | 2 | 01.9 | 2 | 01.9 | 0 | 00.0 | 0 | 00.0 | |||||
Normal | 2 | 01.9 | 97 | 89.8 | 1 | 00.9 | 0 | 00.0 | ||||||
High | 0 | 00.0 | 1 | 00.9 | 3 | 02.8 | 0 | 00.0 | ||||||
Missing | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | 0 | 00.0 | ||||||
Sum | 4 | 03.7 | 100 | 92.6 | 4 | 03.7 | 0 | 00.0 | ||||||
Word automation
This type of table is often too large to be displayed on a single page of a document. We will use a programmatic approach to generate a Word document containing one sub-table per page with some pagination markers or titles.
First, let’s load package ‘officer’ and define a post processing function that will add the page number (as a Word field) in the top line of the table.
library(officer)
set_flextable_defaults(
post_process_docx = function(x) {
x <- add_header_lines(x, "Page N°") |>
append_chunks(i = 1, part = "header", j = 1,
as_word_field(x = "Page")) |>
align(part = "header", align = "right", i = 1) |>
hline_top(part = "header", border = fp_border_default(width = 0))
x
}
)The function that create the flextable for each subset of data is the following:
small_shift_ft <- function(x) {
tab <- tabulator(
x = x,
rows = c("VISIT", "BASELINE"),
columns = c("LBNRIND"),
`n` = as_paragraph(N),
`%` = as_paragraph(as_chunk(PCT, formatter = my_format))
)
ft <- as_flextable(
x = tab, separate_with = "VISIT",
label_rows = c(VISIT = "Visit", BASELINE = "Reference Range Indicator"))
ft
}Then, split or nest sub tables. We will use tidyr::nest().
The Word template being used can be downloaded here: template.docx. We have added our logo and page numbers at the bottom of each page.
subdata <- nest(SHIFT_TABLE, data = all_of(c("VISIT", "BASELINE", "LBNRIND", "N", "PCT")))
doc <- read_docx(path = "template.docx") |>
body_add_par("Table of content", style = "Title") |>
body_add_toc()
for (i in seq_len(nrow(subdata))) {
ft <- small_shift_ft(subdata[[i, "data"]])
doc <- body_add_break(doc) |>
body_add_par(subdata[[i, "LBTEST"]], style = "heading 1") |>
body_add_flextable(ft)
}
print(doc, target = "illustration.docx")The resulting Word document can be downloaded here: illustration.docx. The miniatures below show the expected document.
miniatures of resulting Word document