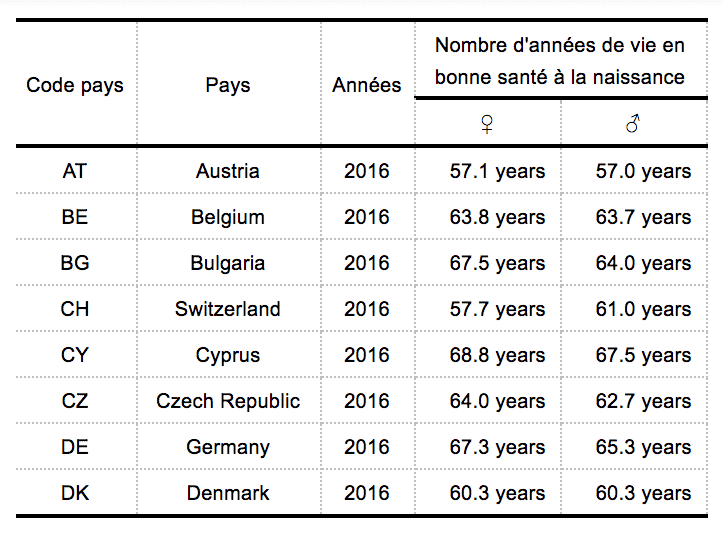
De nouvelles fonctions pour le package flextable sont disponibles depuis sa mise à jour le 31/09/2018. Ce post illustre deux nouvelles fonctionnalités :
- des fonctions pour faciliter la gestion des bordures
- des fonctions pour faciliter le formatage des contenus affichés des colonnes.
Pour l’illustration, on va utiliser des données provenant d’Eurostat.
Nous allons avoir besoin de charger quelques packages :
library(eurostat)
library(tidyr)
library(dplyr)
library(flextable)
library(officer)
library(magrittr)Importons d’abord un jeu de données en utilisant le package eurostat.
raw_data <- get_eurostat(
id = "hlth_hlye", time_format = "num",
filters = list(time = 2016),
stringsAsFactors = FALSE)
eu_countries_ <- bind_rows(
eu_countries, ea_countries,
efta_countries, eu_candidate_countries) %>%
distinct()Voici à quoi ressemblent les données importées :
head(raw_data) %>% flextable()unit | sex | indic_he | geo | time | values |
PC | F | HLY_PC_0 | AT | 2,016 | 67.9 |
PC | F | HLY_PC_0 | BE | 2,016 | 75.8 |
PC | F | HLY_PC_0 | BG | 2,016 | 86.0 |
PC | F | HLY_PC_0 | CH | 2,016 | 67.4 |
PC | F | HLY_PC_0 | CY | 2,016 | 81.1 |
PC | F | HLY_PC_0 | CZ | 2,016 | 78.0 |
head(eu_countries_) %>% flextable()code | name | label |
BE | Belgium | Belgium |
BG | Bulgaria | Bulgaria |
CZ | Czechia | Czechia |
DK | Denmark | Denmark |
DE | Germany | Germany (until 1990 former territory of the FRG) |
EE | Estonia | Estonia |
Utilisons la fonction spread pour transformer les données
en non tidy et faciliter l’affichage.
dat <- raw_data %>%
filter(indic_he %in% "HLY_PC_0", unit %in% "PC", sex %in% c("F", "M")) %>%
inner_join(eu_countries_, by = c("geo" = "code")) %>%
mutate(sex = paste0(sex, "_0_DFLE")) %>%
pivot_wider(id_cols = c(geo, name), names_from = sex, values_from = values)
head(dat) %>% flextable()geo | name | F_0_DFLE | M_0_DFLE |
AT | Austria | 67.9 | 71.9 |
BE | Belgium | 75.8 | 80.6 |
BG | Bulgaria | 86.0 | 89.8 |
CH | Switzerland | 67.4 | 74.7 |
CY | Cyprus | 81.1 | 83.9 |
CZ | Czechia | 78.0 | 82.4 |
Et maintenant on va créer un flextable :
flex_data <- head(dat, n=8) %>%
flextable(col_keys = c("geo", "name", "F_0_DFLE", "M_0_DFLE"))
flex_data <- set_header_labels(
flex_data, geo = "Code pays", name = "Pays",
F_0_DFLE = "\U2640", M_0_DFLE = "\U2642" )
flex_data <- add_header(flex_data, geo = "Code pays", name = "Pays",
F_0_DFLE = "Nombre d'années de vie en bonne santé à la naissance",
M_0_DFLE = "Nombre d'années de vie en bonne santé à la naissance" ,
top = TRUE)
flex_data <- merge_h(flex_data, part = "header")
flex_data <- merge_v(flex_data, part = "header")
flex_data <- align(flex_data, j = c("geo", "name"), align = 'center', part = "all")
flex_data <- align(flex_data, j = c("F_0_DFLE", "M_0_DFLE"),
align = 'right', part = "all")
flex_data <- padding(flex_data, padding.left = 5, padding.right = 5)
flex_dataCode pays | Pays | Nombre d'années de vie en bonne santé à la naissance | |
♀ | ♂ | ||
AT | Austria | 67.9 | 71.9 |
BE | Belgium | 75.8 | 80.6 |
BG | Bulgaria | 86.0 | 89.8 |
CH | Switzerland | 67.4 | 74.7 |
CY | Cyprus | 81.1 | 83.9 |
CZ | Czechia | 78.0 | 82.4 |
DE | Germany | 80.7 | 83.1 |
DK | Denmark | 72.8 | 76.3 |
Les nouvelles fonctions intégrées au package
colformat_*,vline,hlineont été créées dans le but de faciliter la mise en forme desflextables.
hline et vline
Commençons par modifier les bordures à l’aide des fonctions hline et vline.
Ces fonctions vont permettre de mettre en forme les interlignes horizontales et
verticales du tableau. Il est possible de choisir la partie du tableau concernée
par les modifications grâce au paramètre part =, soit “all”, “body”, “header”
ou “footer”.
dash_border <- fp_border(color = "gray", style = "dashed")
big_border <- fp_border(color = "black", width = 2)
flex_data <- vline(x = flex_data, j = 1:4, border = dash_border ,part = "all")
flex_data <- hline(x = flex_data, border = dash_border, part = "body")
flex_data <- hline_bottom(x = flex_data, border = big_border, part = "all")
flex_dataCode pays | Pays | Nombre d'années de vie en bonne santé à la naissance | |
♀ | ♂ | ||
AT | Austria | 67.9 | 71.9 |
BE | Belgium | 75.8 | 80.6 |
BG | Bulgaria | 86.0 | 89.8 |
CH | Switzerland | 67.4 | 74.7 |
CY | Cyprus | 81.1 | 83.9 |
CZ | Czechia | 78.0 | 82.4 |
DE | Germany | 80.7 | 83.1 |
DK | Denmark | 72.8 | 76.3 |
colformat_*
Avant la dernière mise à jour, pour modifier l’affichage des données (quelle que soit la ligne ou la colonne) d’un flextable, comme supprimer les décimales pour la colonne années, ajouter une image, etc., nous pouvions utiliser la fonction display.
Pour l’affichage des données d’un flextable (uniquement par colonnes), nous pouvions utiliser la
fonction set_formatter.
flex_data <- display(
flex_data,
col_key = "time",
pattern = "{{value}}",
formatters = list(
value ~ sprintf("%.0f", time)
)
)
flex_dataApparement, utiliser display ou set_formatter c’est complexe. Plusieurs questions ont été posées sur
stackoverflow-flextable et nous avons vu apparaître le besoin d’une fonction plus simple d’utilisation.
Ces fonctions sont très puissantes mais la majorité des besoins utilisateurs sont simples et devraient
être possible avec peu de code. L’exemple ci-dessus le met plutôt bien en évidence, il y a beaucoup de
code à taper alors que l’ordre à donner est simple: La colonne time doit être formatée avec l’appel sprintf("%.0f", time).
Afin d’offrir une fonction de formatage plus simple à utiliser, les fonctions colformat_* ont été créées.
Les fonctions colformat_* permettent de mettre facilement en forme le contenu des colonnes.
Si plusieurs colonnes vont être modifiés de la même manière, il est possible de le faire dans la même
instruction colformat_*.
L’option suffix = nous permet d’ajouter une valeur supplementaire à toutes les modalités d’une colonne,
ici, nous ajoutons le suffixe years aux variables numeriques F_0_DFLE et M_0_DFLE.
Les options big.mark = et digits = modifient l’apparence des modalités numériques, big.mark = indiquera
le séparateur des milliers et digits = permettra de choisir le nombre de chiffres après la virgule qui sera
affiché.
flex_data <- colformat_num(x = flex_data,
j = c("F_0_DFLE", "M_0_DFLE"),
suffix = " years", na_str = "-", digits = 1)
flex_data <- autofit(flex_data)
flex_data <- width(flex_data, j = 3:4, width = 1)
flex_data <- hline_top(flex_data, part = "all", border = big_border )
flex_dataCode pays | Pays | Nombre d'années de vie en bonne santé à la naissance | |
♀ | ♂ | ||
AT | Austria | 67.9 years | 71.9 years |
BE | Belgium | 75.8 years | 80.6 years |
BG | Bulgaria | 86.0 years | 89.8 years |
CH | Switzerland | 67.4 years | 74.7 years |
CY | Cyprus | 81.1 years | 83.9 years |
CZ | Czechia | 78.0 years | 82.4 years |
DE | Germany | 80.7 years | 83.1 years |
DK | Denmark | 72.8 years | 76.3 years |
Merci aux utilisateurs pour leur feedback, à plus tard pour d’autres news.